Thanks to Jeremy Epstein (go-to for all things blockchain) for drawing my attention to this Wired interview with Emmanuel Macron. Here is a man who understands the world of the algorithm. There are three reasons you can tell this. First: he doesn’t talk about trying to lock-up access to data – he talks about making data open (with conditions attached – primarily transparency). Second: from a regulatory perspective he focuses on the importance of transparency and shows he understands the dangers of a world where responsibility is delegated to algorithms. Third: he talks about the need for social consent, and how lack thereof is both a danger to society but also to the legitimacy (and thus ability to operate) of the commercial operators in the space (I was 7 years ahead of you here Emmanuel).
As an example, he is opening access to public data on the condition that any algorithms that feed on this data are also made open. This is an issue that I belive could be absolutely critical. As I have said before, algorithms are the genes of a datafied society. In much the same way that some commercial organisations tried (and fortunately failed) to privatise pieces of our genetic code, there is a danger that our social algorithmic code could similarly be removed from the public realm. This isn’t to say that all algorithms should become public property but they should be open to public inspection. It is usage of algorithms that require regulatory focus, not usage of data.
This is a man who understands the role of government in unlocking the opportunities of AI, but also recognises the problems government has a duty to manage. It is such a shame that there are so few others (especially in the UK where the government response is child-like, facile and utterly dissmisive of the idea that government has any role to play other than to let ‘the market’ run its course whilst making token gestures of ‘getting tough‘).
The GDPR (as played by King Canute) and the rising tide of data (as played by The Sea)
Mark Zuckerberg’s appearance before Congress is a good example of the extent to which politicians and regulators have no idea, to quote The Donald, of “what on earth is going on”. It is not just them, this lack of understanding extends into the communities of thought and opinion framed by academia and journalism. This is a problem, because it means we have not yet identified the questions we need to be asking or the problems we need to be solving. If we think we are going to achieve anything by hauling Mark Zuckerberg over the coals, or telling Facebook to “act on data privacy or face regulation”, we have another think coming.
This is my attempt to provide that think.
The Google search and anonymity problem
Let’s start with Google Search. Imagine you sit down at a computer in a public library (i.e. a computer that has no data history associated with you) and type a question into Google. In this situation you are reasonably anonymous, especially if we imagine that the computer has a browser that isn’t tracking track search history. Despite this anonymity, Google can serve you up an answer that is incredibly specific to you and what it is you are looking for. Google knows almost nothing about you, yet is able to infer a very great deal about you – at least in relation to the very specific task associated with finding an answer to your question. It can do this because it (or its algorithms) ‘knows’ a very great deal about everyone or everything in relation to this specific search term.
So what? Most people sort of know this is how Google works and understand that Google uses data derived from how we all use Google, to make our individual experiences of Google better. But hidden within this seemingly benign and beneficial use of data is the same algorithmic process that could drive cyber warfare or mass surveillance. It therefore has incredibly important implications for how we think about privacy and regulation, not least because we have to find a way to outlaw the things we don’t like, while still allowing the things that we do (like search). You could call this the Google search problem or possibly the Google anonymity problem, because it demonstrates that in the world of the algorthm, anonymity has very little meaning and provides very little defence.
The Stasi problem
When you frame laws or regulations you need to start with defining what sort of problem you are trying to solve or avoid. To date the starting point for regulations on data and privacy (including the GDPR – the regulation to come) is what I call the STASI problem. The STASI was the East German Security Service and it was responsible for a mass surveillance operation that encouraged people to spy on each other and was thus able to amass detailed data files on a huge number of its citizens. The thinking behind this, and indeed the thinking applied to the usage of personal data everywhere in the age before big data, is that the only way to ‘know’ stuff about a person is to collect as much information about them as possible. The more information you have, the more complete the story and the better your understanding. At the heart of this approach is the concept that there exists in some form a data file on an individual which can be interrogated, read or owned.
The ability of a state or an organisation to compile such data files was seen as a bad thing and our approach to data regulation and privacy has therefore been based on trying to stop this from happening. This is why we have focused on things like anonymity, in the belief that a personal data file without a name attached to it becomes largely useless in terms of its impact on the individual to whom the data relates. Or we have established rights that allow us to see these data files, so that we can check that they don’t contain wrong information or give us the ability to edit, correct or withdraw information. Alternatively, regulation has sought to establish rights for us to determine how our the data in the file data is used or for us to have some sort of ownership or control over that data, wherever they may be held.
But think again about the Google search example. Our anonymity had no material bearing on what Google was able to do. It was able to infer a very great deal about us – in relation to a specific task – without actually knowing anything about us. It did this because it knew a lot about everything, which it had gained from gathering a very small amount of data from a huge number of people (i.e. everyone who had previously entered that same search term). It was analysing data laterally, not vertically. This is what I call Google anonymity, and it is a key part of Google’s privacy defence when it comes to things such as gmail. If you have a gmail account, Google ‘reads’ all your emails. If you have Google keyboard on your mobile, Google ‘knows’ everything that you enter into your mobile (including the passwords to your bank account) – but Google will say that it doesn’t really know this because algorithmic reading and knowledge is a different sort of thing. We can all swim in a sea of Google anonymity right up until the moment a data fisherman (such as a Google search query) gets us on the hook.
The reason this defence (sort of) stacks-up is that Google can only really know your bank account password is if it analyses your data vertically. The personal data file is a vertical form of data analysis. It requires that you mine downwards and digest all the data to then derive any range of conclusions about the person to whom that data corresponds. It has its limitations, as the Stasi found out, in that if you collect too much data you suffer from data overload. The bigger each file becomes the more cumbersome it is to read or digest the information that lies within it. It is a small data approach. Anyone who talks about data overload or data noise is a small data person.
Now while it might have been possible to get the Stasi to supply all the information it has on you, the idea that you place the same requirement on Google is ridiculous. If I think about all the Google services I use and the vast amount of data this generates, there is no way this data could be assembled into a single file and even if it could, it would have no meaning, because the way it would be structured has no relevance to the way in which Google uses this data. Google already has vastly more data on me than the biggest data file the STASI ever had on a single individual. But this doesn’t mean that Google actually knows anything about me as an individual. I still have a form of anonymity, but this anoymity is largely useless because it has no bearing on the outcomes that derive from the usage of my data.
The KitKat Problem
Algorithms don’t suffer from data overload, not just because of the speed at which they can process information but because they are designed to create shortcuts through the process of correlations and pattern recognition. One of the most revealing nuggets of information within Carole Cadwalladr’s expose of the Facebook / Cambridge Analytica ‘scandal’ was the fact that a data agency of the like of Cambridge Analytica working for a state intelligence service had discovered a correlation between people who self-confess to hating Israel and a tendency to like Nike trainers and KitKats. This exercise, in fact, became known as Operation KitKat. To put it another way, with an algorithm it is possible to infer something very consequential about someone (that they hate Israel) not by a detailed analysis of their data file, but by looking at consumption of chocolate bars. This is an issue I first flagged back in 2012.
I think this is possibly the most important revelation of the whole saga, because, as with the Google search example it cuts right to the heart of the issue and exposes the extent to which our current definition of the problem is so misplaced. We shouldn’t be worrying about the STASI problem, we should be worried about the KitKat problem. Operation KitKat demonstrates two of the fundamental characteristics of algorithmic analysis (or algorithmic surveillance). First, not only can you derive something quite significant about a person based on data that has nothing whatsoever to do with what it is you are looking for. Second, algorithms can tell you what to do (discover haters of Israel by looking at chocolate and trainers) without the need to understand why this works. An algorithm cannot tell you why there is a link between haters of Israel and KitKats. There may not even be reason that makes any sort of sense. Algorithms cannot explain themselves, they leave no audit trail – they are the classic black box.
The reason this is so important is that it drives a cart and horse through any form of regulation that tries to establish a link between any one piece of data and the use to which that data is then put. How could one create a piece of legislation that requires manufacturers or retailers of KitKats to anticipate (and otherwise encourage or prevent) data about their product being used to identify haters of Israel? It also scuppers the idea that any form protection can be provided through the act of data ownership. You cannot make the consumption of a chocolate bar or the wearing of trainers a private act, the data on which is ‘owned’ by the people concerned.
KitKats and trainers bring us neatly to the Internet of Things. Up until now we have been able to assume that most data is created by, or about, people. This is about to change as the amount of data produced by people is dwarfed by the amount of data produced by things. How do we establish rules about data produced by things especially when it is data about other things? If your fridge is talking to your lighting about your heating thermostat, who owns that conversation? There is a form of Facebook emerging for objects and it is going to be much bigger than the Facebook for people.
Within this world the concept of personal data as a discrete category will melt away and instead we will see the emergence of vaste new swathes of data, most of which is entirely unregulatable or even unownable.
The digital caste problem
A recent blog post by Doc Searls has made the point that what Facebook has been doing is simply the tip of an iceberg, in that all online publishers or any owners of digital platforms are doing the same thing to create targeted digital advertising opportunities. However, targeted digital advertising is itself the tip of a much bigger iceberg. One of Edward Snowden’s Wikileaks exposures concerned something known as Operation Prism. This was (probably still is) a programme run by the NSA in the US that involves the abilty to hoover-up huge swathes of data from all of the world’s biggest internet companies. Snowden also revealed that the UK’s GCHQ is copying huge chunks of the internet by accessing the data cables that carry internet traffic. This expropriation of data is essentially the same as Cambridge Analytica’s usage of the ‘breach’ of Facebook data, except on a vastly greater scale. Cambridge Analytica used their slice of Facebook to create a targeting algorithm to analyse political behaviour or intentions, whereas GCHQ or the NSA can use their slice of the internet to create algorithms that analyse the behaviour or intentions of all of us about pretty much anything. Apparently GCHQ only holds the data it copies for a maximum of 30 days, but once you have built your algorithms and are engaged in a process of real-time sifting, the data that you used to build the agorithm in the first place, or the data that you then sift through it, is of no real value anymore. Retention of data is only an issue if you are still thinking about personal data files and the STASI problem.
This is all quite concerning on a number of levels, but when it comes to thinking about data regulation it highlights the fact that, provided we wish to maintain the idea that we live in a democracy where governments can’t operate above the law, any form of regulation you might decide to apply to Facebook and any current or future Cambridge Analyticas also has to apply to GCHQ and the NSA. The NSA deserves to be put in front of Congress just as much as Mark Zuckerberg.
Furthermore, it highlights the extent to which this is so much bigger than digital advertising. We are moving towards a society structured along lines defined by a form of digital caste system. We will all be assigned membership of a digital caste. This won’t be fixed but will be related to specific tasks in the same way that Google search’s understanding of us is related to the specific task of answering a particular search query. These tasks could be as varied as providing us with search results, to deciding whether to loan us money, or whether we are a potential terrorist. For some things we may be desirable digital Brahmins, for others we may be digital untouchables and it will be algorithms that will determine our status. And the data the algorithms use to do this could come from KitKats and fridges – not through any detailed analysis of our personal data files. In this world the reality of our lives becomes little more than personal opinion: we are what the algorithm says we are, and the algorithm can’t or won’t tell us why it thinks that. In a strange way, creating a big personal data file and making this available is the only way to provide protection in this world so that we can ‘prove’ our identity (cue reference to a Blockchain solution which I could devise if I knew more about Blockchains), rather than have an algorithmic identity (or caste) assigned to us. Or to put it another way, the problem we are seeking to avoid could actually be a solution to the real problem we need to solve.
The digital caste problem is the one we really need to be focused on.
The challenge
So – the challenge is how do we prevent or manage the emergence of a digital caste system. And how do we do this in a way which still allows Google search to operate, doesn’t require that we make consumption of chocolate bars a private act or regulate conversations between household objects (and all the things on the Internet of Things) and can apply both to the operations of Facebook and the NSA. I don’t see any evidence thus far the the great and the good have any clue that this is what they need to be thinking about. If there is any clue as to the direction of travel it is that the focus needs to be on the algorithms, not the data they feed on.
We live in a world of a rising tide of data, and trying to control the tides is a futile exercise, as Canute the Great demonstrated in the 11th century. The only difference between then and now is that Canute understood this, and his exercise in placing his seat by the ocean was designed to demostrate the limits of kingly power. The GDPR is currently dragging its regulatory throne to the waters edge anticipating an entirely different outcome.
For the last year Carole Cadwalladr at the Observer has been doing a very important job exposing the activities of Cambridge Analytica and its role in creating targeted political advertising using data sourced, primarily, from Facebook. It is only now, with the latest revelations published in this week’s Observer, that her work is starting to gain political traction.
This is an exercise in shining a light where a light needs to be shone. The problem however is in illuminating something that is actually illegal. Currently the focus is on the way in which CA obtained the data it then used to create its targeting algorithm and whether this happened with either the consent or knowledge of Facebook or the individuals concerned. But this misses the real issue. The problem with algorithms is not the data that they feed on. The problem is that an algorithm, by its very nature, drives a horse and cart through all of the regulatory frameworks we have in place, mostly because these regulations have data as their starting point. This is one of the reasons why the new set of European data regulations – the GDPR – which come in to force in a couple of months, are unlikely to be much use in preventing US billionaires from influencing elections.
If we look at what CA appear to have been doing, laying aside the data acquisition issue, it is hard to see what is actually illegal. Facebook has been criticised for not being sufficiently rigourous in how it policed the usage of its data but, I would speculate, the reason for this is that CA was not doing anything particularly different from what Facebook itself does with its own algorithms within the privacy of its own algorithmic workshops. The only difference is that Facebook does this to target brand messages (because that is where the money is), whereas CA does it to target political messages. Since the output of the CA activity was still Facebook ads (and thus Facebook revenue), from Facebook’s perspective their work appeared to be little more that a form of outsourcing and thus didn’t initially set-off any major alarm bells.
This is the problem if you make ownership or control of the data the issue – it makes it very difficult to discriminate between what we have come to accept as ‘normal’ brand activities and cyber warfare. Data is data: the issue is not who owns it, it is what you do with it.
We are creating a datafied society, whether we like it or not. Data is becoming ubiquitous and seeking to control data will soon be recognised as a futile exercise. Algorithms are the genes of a datafied society: the billons of pieces of code that at one level all have their specific, isolated, purpose but which, collectively, can come to shape the operation of the entire organism (that organism being society itself). Currently, the only people with the resources or incentive to write society’s algorithmic code are large corporations or very wealthy individuals and they are doing this, to a large extent, outside of the view, scope or interest of either governments or the public. This is the problem. The regulatory starting point therefore needs to be the algorithms, not the data, and creating both transparency and control over their ownership and purpose.
Carol’s work is so important because it brings this activity into view. We should not be distracted or deterred by the desire to detect illegality because this ultimately plays to the agenda of the billionaires. What is happening is very dangerous and that danger cannot be contained by the current legal cage, but it can be constrained by transparency.
Not far short of three years-ago I published a piece on the Huffington Post which suggested that humans had moved from the age of the sword into the age of the printing press and were about to move into the age of the algorithm. The reason, I suggested, for why a particular form of technology came to shape an age was that each technology conferred an advantage upon an elite or institutionalised group, or at least facilitated the emergence of a such group which could control these technologies in order to achieve dominance.
This is why the algorithm will have its age. Algorithms are extraordinarily powerful but they are difficult things to create. They require highly paid geeks and therefore their competitive advantage will be conferred on those with the greatest personal or institutionalised resource – billionaires, the Russians, billionaire Russians, billionaire Presidents (Russian or otherwise). There is also a seductive attraction between algorithms and subterfuge: they work most effectively when they are invisible. Continue reading →
I notice that I last posted in June last year and that this wasn’t even a proper post, just a reference to a speech I had given in Istanbul that was conveniently YouTubed. In my defence, I have been busy doing other things such as building a house and involved in an interesting experiment in online education. Interestingly, my blog views haven’t decreased dramatically over that time, which I think says something instuctive about the whole content thing. It suggests that content is not a volume game, where frequency or even timing of posting is key, rather it suggests that content is a relevance game that is not driven by the act of publication, but driven by the act of search. This is why content socialisation is far more important that content publication. As I have said before, spend only 10 per cent (or less) of your content budget actually producing content and the remaining 90 per cent on socialising that content. Socialised content is the gift that carries on giving. Once it is out there it will carry on working for you without you having to do anything else. And this socialisation has to start with an understanding of what content (information) people actually want from you – identifying the questions for which your brand is the answer. Remember, the social digital space is not a distribution space where reach and frequency are the objectives, it is a connection space where the objectives are defined by behaviour identification and response.
Here endeth the predictable critique of content strategies.
Given that it is still January I believe I have permission to resume posting with a 2017 prediction piece. I was prompted to do this by reading Ashley Freidlin’s extremely comprehensive post on marketing and digital trends for 2017. This is essentially a review of the landscape and it its sheer scale is almost guaranteed to strike terror into the heart of every marketing director. Perhaps because of this, Ashley’s starts with saying that the guiding star for 2017 should be focus, so in that spirit I shall attempt to provide some basis for focus. Continue reading →
A couple of weeks ago I stumbled across something called Google Big Query and it has changed my view on data. Up until that point I had seen data (and Big Data) as something both incredibly important and incredibly remote and inaccessible (at least for an arts graduate). However, when I checked-out Google Big Query I suddenly caught a glimpse of a future where an arts graduate can become a data scientist.
Google Big Query is a classic Google play in that it takes something difficult and complicated and rehabilitates it into the world of the everyday. I can’t pretend I really understood how to use Google Big Query, but I got the strong sense that I wasn’t a million miles away from getting that understanding – especially if GBQ itself became a little more simplified.
And that presents the opportunity to create a world where the ability to play with data is a competence that is available to everyone. Google Big Query could become a tool as familiar to the business world as PowerPoint or Excel. Data manipulation and interrogation will become a basic business competence, not just a rarefied skill.
The catch, of course, is that this opportunity is only available to you once you have surrendered your data to the Google Cloud (i.e. to Google) and paid for an entry visa. As it shall at the base of the Statue of Googlability that marks the entry point to the US of D:
“Give me your spreadsheets, your files,
Your huddled databases yearning to breathe free,
The wretched data refuse of your teeming shore.
Send these, the officeless, ppt-tossed, to me:
I lift my algorithms beside the (proprietary) golden door.”
And the rest, as they say, shall be history (and a massive future revenue stream).
Last week the BBC looked at artificial intelligence and robotics. You could barely move through any part of the BBC schedule on any of its platforms without encountering an AI mention or feature. A good idea I think – both an innovative way of using ‘the whole BBC’ but also an important topic. That said I failed to come across any piece which adequately addressed what I believe is the real issue of AI and how it is likely to play-out and influence humanity.
True to subject form, in the BBC reporting there was a great deal of attention on ‘the machine’ and ‘the robot’ and the idea that intelligence has to be defined in a human way and therefore artificial intelligence can be said to be here, or to pose a threat, when some machine has arrived which is a more intelligent version of a human. This probably all stems from the famous Turing test together with the fact that most of the thinkers in the AI space are machine (i.e. computer) obsessives: artificial intelligence and ‘the machine’ are therefore seen to go hand in hand. But AI is not going to arrive via some sort of machine, in fact it will be characterised by the absence of any visible manifestations because AI is all about algorithms. Not algorithms that are contained within or defined by individual machines or systems, but algorithms unconstrained by any individual machine and where the only system is humanity itself. Here is how it will play-out. Continue reading →
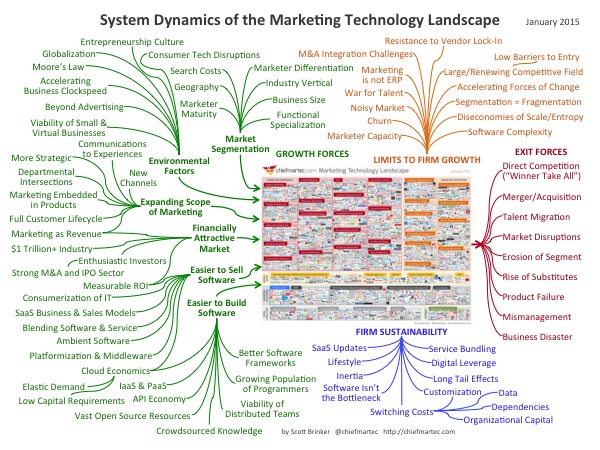
This post is a marker. It is post-it note that says “remember to watch this space and try and get your head around it because this is going to be big”. It also is an excuse to log what I think is a very useful, if slightly mind-bending post by Scott Brinker.
My current mantra for marketing folk is that the future of brands involves getting your head around three things: the shift from the audience to the individual, the fact that community is becoming the new media, and the emergence of the world of the algorithm (i.e. Big Data). I also continually bang-on about social media being a process, and of course, one of the things we use technology to do is management of process.
To a large extent, eveything that Scott is talking about in his post plays against these issues. To manage relationships with individuals at any sort of scale will require a process supported by technology. Scott also talks about tag management – which (as I have already written about) will become the foundational process for the operation of communities. Likewise, it is clear that the algorithm will become the tool that makes sense of the data that could be seen to live within the marketing cloud. And, as Scott points out, Amazon is already starting to offer algorithmic products to do just that.
Scott also observes that things are currently very complicated and confused. Or, as I flagged in my previous post, this stuff is ‘legitimately difficult’. I definitely do no know enough about it – but from what I can see, I think I know enough to say that this is the future. Technology is going to play a huge role in the management of the relationship between brands and consumers – because technology facilitates process, and this future relationship is going to be defined by process (behaviour identification and response) not by channel and message.
I think I can also predict that the key to really embracing this future is to shed yourself of the snakeskin of the past. Big data is totally different to small data, to the extent that you can’t build your way to a big data future from a small data starting point or mindset. Likewise, current marketing technology deals with stuff like CRM but the only way you will be able to deal with the new marketing technology is to free yourself from a CRM mindset (and possibly your CRM people). If you look at this new stuff through the lens of the old stuff, you will probably fail to see or understand its potential.
Yesterday the UK Parliament’s Intelligence and Security Committee published its report into the security services. The thrust of this investigation was to look at the whole issue of the bulk interception of data – an issue dragged into the limelight by Edward Snowden – and determine whether this constitutes mass surveillance. (See this post for more detail on the difference, or not, between bulk interception of data and mass surveillance).
What the report has really done is both flush out some important issues, but then allow these to remain hidden in plain sight, because the Committee has failed to grasp the implications of what they have uncovered.
The BBC summarises the key point thus: (The Committee) said the Government Communications Headquarters (GCHQ) agency requires access to internet traffic through “bulk interception” primarily in order to uncover threats by finding “patterns and associations, in order to generate initial leads”, which the report described as an “essential first step.”
And here is what is hiding in plain sight. The acknowledgment that GCHQ is using bulk data to “find patterns and associations in order to generate initial leads.” What is wrong with that, you might say? Here is what is wrong with that. This means that information gained by swallowing (intercepting) large chunks of humanity’s collective digital activity is being used to predict the possibility that each and everyone of us (not just those whose data might have been swallowed) is a … fill in the gap (potential terrorist, criminal, undesirable). We all now wear a badge, or can have such a badge put upon us, which labels us with this probability. Now it may well be that only those of us that have a badge with a high probability then go on to become ‘initial leads’ (whose emails will then be read). But we all still wear the badge and we can all go on to become an initial lead at some point in the future, dependant on what specific area of investigation an algorithm is charged with investigating.
Algorithmic surveillance is not about reading emails, as the Committee (and many privacy campaigners) seem to believe. This is an old fashioned ‘needles in haystacks’ view of surveillance. Algorithmic surveillance is not about looking for needles in haystacks, it is about using data from the hay in order to predict where the needles are going to be. In this world the hay becomes the asset. Just because GCHQ is not ‘reading’ all our emails doesn’t legitimise the bulk interception of data or provide assurance that a form of mass surveillance is not happening. As I said in the previous post: until we understand what algorithmic surveillance really means, until this is made transparent, society is not in a position to give its consent to this activity.
Where does bulk interception of data stop and mass surveillance start and in the world of Big Data and algorithmic surveillance is it even relevant to make such a distinction?
It emerged last week that these are important questions, following a ruling by the UK’s Investigatory Powers Tribunal and subsequent response by the UK government and its electronic spying outfit, GCHQ (see the details in this Guardian report). This response proposes that mass surveillance doesn’t really happen (even if it may look a bit like it does), because all that is really going on is bulk interception of data and this is OK (and thus can be allowed to happen).
One of the most disturbing revelations flowing from Edward Snowden’s exposure of the Prism and Upstream digital surveillance operations is the extent to which the US and UK governments have been capturing and storing vast amounts of information, not just on possible terrorists or criminals, but on everyone. This happened in secret and its exposure has eventually prompted a response from government and this response has been to assert that this collection and storage doesn’t constitute mass surveillance, instead it is “the bulk interception of data which is necessary to carry out targeted searches of data in pursuit of terrorist or criminal activity.”
This is the needle in the haystack argument – i.e. we need to process a certain amount of everyone’s hay in order to find the terrorist needles that are hidden within it. This seems like a reasonable justification because it implies that the hay (i.e. the information about all of us) is a disposable asset, something to be got rid of in order to expose the needles. This is basically the way that surveillance has always operated. To introduce another analogy, it is a trawling operation that is not interested in the water that passes through the net only the fish that it contains.
However, this justification falls down because this is not the way that algorithmic surveillance works. Algorithmic surveillance works by Continue reading →

 Thanks to Jeremy Epstein (go-to for all things blockchain) for drawing my attention to this Wired interview with Emmanuel Macron. Here is a man who understands the world of the algorithm. There are three reasons you can tell this. First: he doesn’t talk about trying to lock-up access to data – he talks about making data open (with conditions attached – primarily transparency). Second: from a regulatory perspective he focuses on the importance of transparency and shows he understands the dangers of a world where responsibility is delegated to algorithms. Third: he talks about the need for social consent, and how lack thereof is both a danger to society but also to the legitimacy (and thus ability to operate) of the commercial operators in the space (I was 7 years ahead of you here Emmanuel).
Thanks to Jeremy Epstein (go-to for all things blockchain) for drawing my attention to this Wired interview with Emmanuel Macron. Here is a man who understands the world of the algorithm. There are three reasons you can tell this. First: he doesn’t talk about trying to lock-up access to data – he talks about making data open (with conditions attached – primarily transparency). Second: from a regulatory perspective he focuses on the importance of transparency and shows he understands the dangers of a world where responsibility is delegated to algorithms. Third: he talks about the need for social consent, and how lack thereof is both a danger to society but also to the legitimacy (and thus ability to operate) of the commercial operators in the space (I was 7 years ahead of you here Emmanuel).


 Yesterday the UK Parliament’s Intelligence and Security Committee published its report into the security services. The thrust of this investigation was to look at the whole issue of the bulk interception of data – an issue dragged into the limelight by Edward Snowden – and determine whether this constitutes mass surveillance. (See
Yesterday the UK Parliament’s Intelligence and Security Committee published its report into the security services. The thrust of this investigation was to look at the whole issue of the bulk interception of data – an issue dragged into the limelight by Edward Snowden – and determine whether this constitutes mass surveillance. (See